← All hackathons

 $128$22
$128$22
Ended
Hack #4: turbopuffer
Challenge
Build something with turbopuffer and ElevenLabs APIs
Prizes
$15,292 total1st Place
$9,182$8,192 in turbopuffer credits + LEGO kit
3 months ElevenLabs Scale ($990)
2nd Place
$4,756$4,096 in turbopuffer credits
2 months ElevenLabs Scale ($660)
3rd Place
$1,354$1,024 in turbopuffer credits
1 month ElevenLabs Scale ($330)
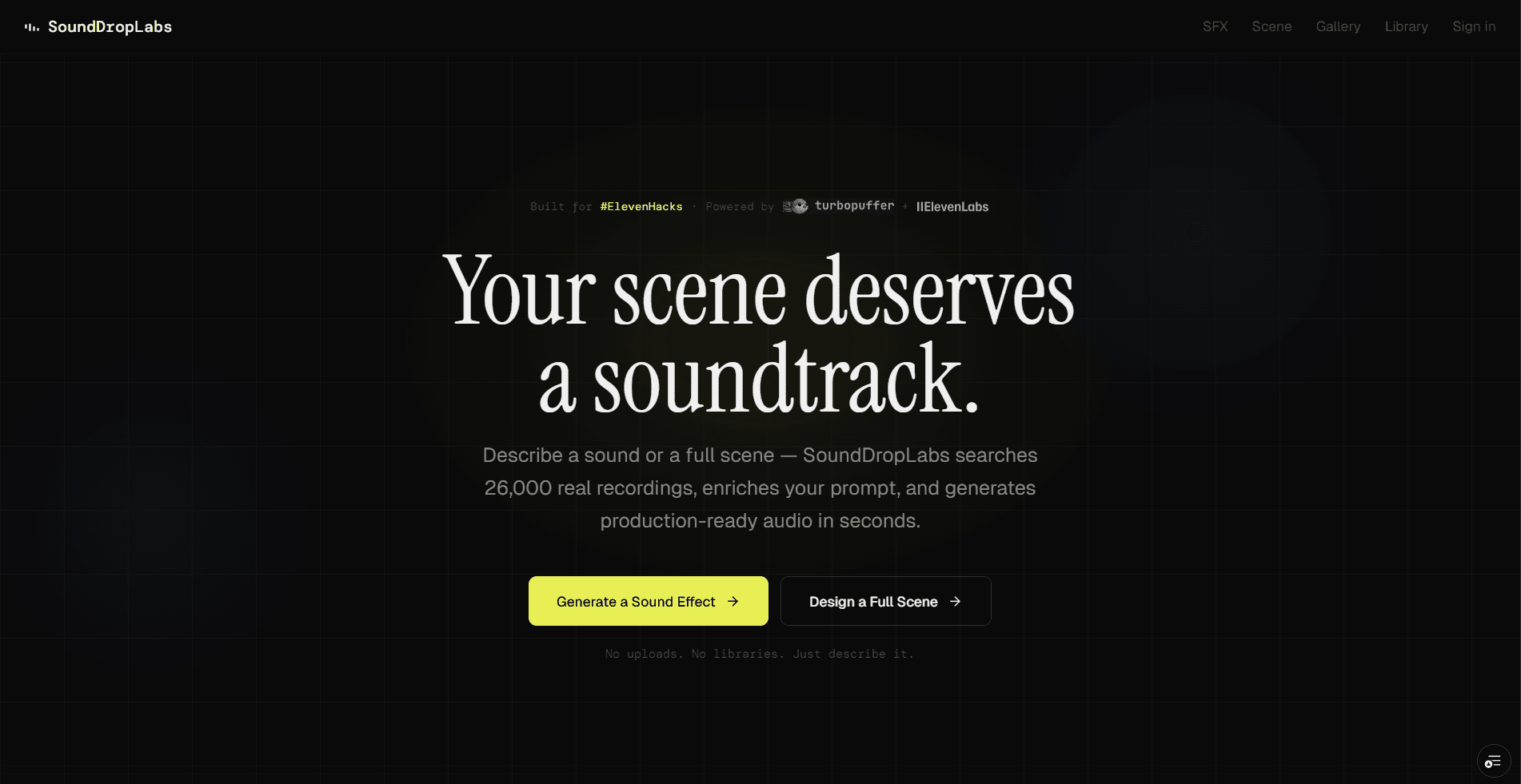
Build something creative using turbopuffer's vector search and ElevenLabs APIs, then submit a high-quality viral-style video demonstrating what you've built.
turbopuffer is the search engine to connect large amounts of unstructured data to AI. Built from first principles on object storage with an intelligent cache layer, turbopuffer is just as fast as in-memory search engines but orders of magnitude cheaper to run — indexing over 3 trillion documents for leading AI companies.
ElevenLabs offers state-of-the-art audio AI. The Sound Effects API generates any sound effect from a text prompt. The Music API creates original music tracks from descriptions. Combine turbopuffer's semantic search with ElevenLabs' audio generation to build something unique.
What we're looking for
We're particularly excited about music and sound effects use-cases. Show us creative combinations of vector search and audio AI — recommendations, RAG for audio, or anything that benefits from connecting unstructured data to ElevenLabs' generation capabilities.
Getting started
Sign up on the turbopuffer event page to get $128 in credits for your first month while you prototype. Already a turbopuffer customer? Email hacks@turbopuffer.com to request your hackathon credits.
Resources
Tag us
When posting your submission on social media, tag @turbopuffer and @elevenlabsio and use the hashtag #ElevenHacks.
Scoring
- Social posts: +50 pts per platform (X, LinkedIn, Instagram, TikTok)
- Placement: 1st place +400 pts, 2nd +200 pts, 3rd +150 pts
- Most Viral: +200 pts for the post with the most engagement
- Most Popular: +200 pts (community vote via emoji reacts)


Attendee offers
$128 in turbopuffer credits
Sign up on the event page for $128 in credits for your first month
Sign in to claim this offer
1 month ElevenLabs Creator
Free month of ElevenLabs Creator plan for all attendees
Sign in to claim this offer
Submissions (37)
J
Jimmy Arroyo
16 Apr, 12:36
🏆1st
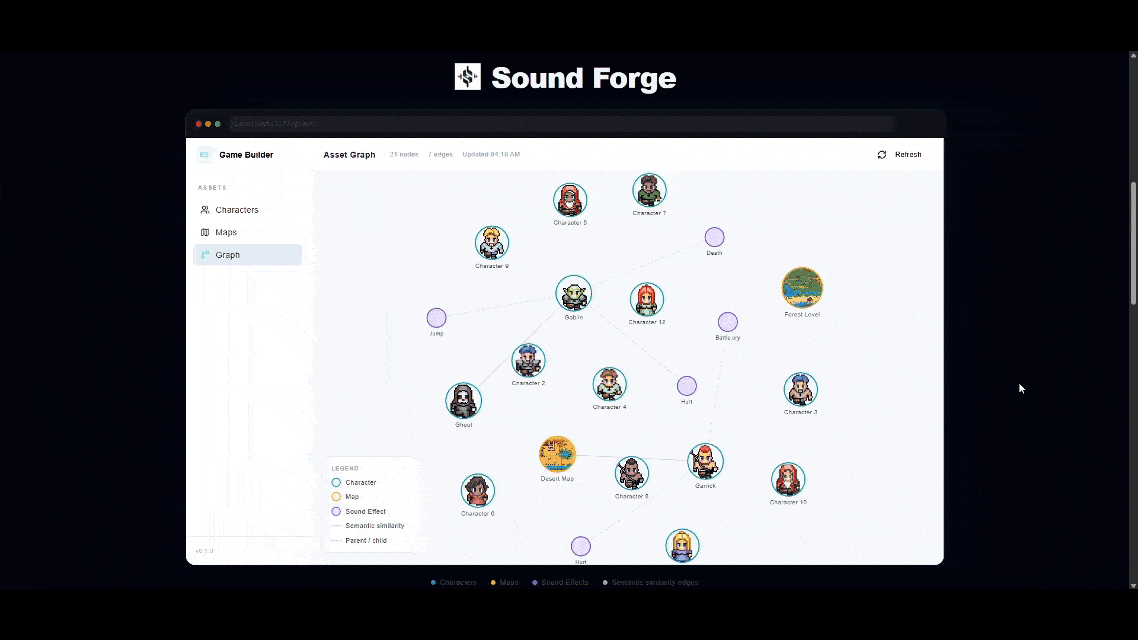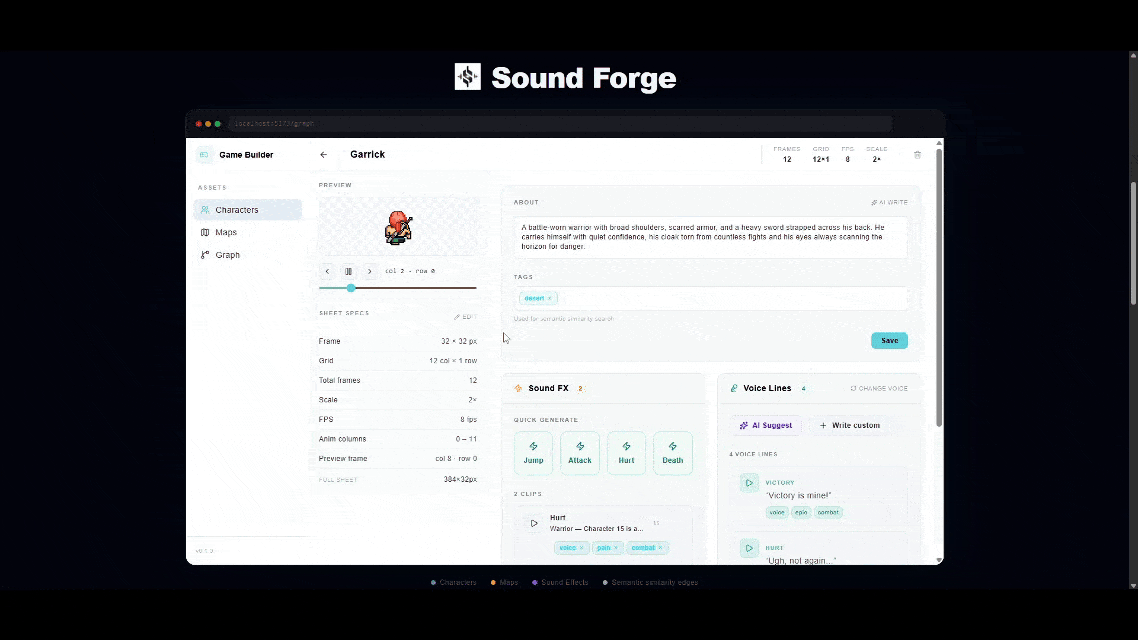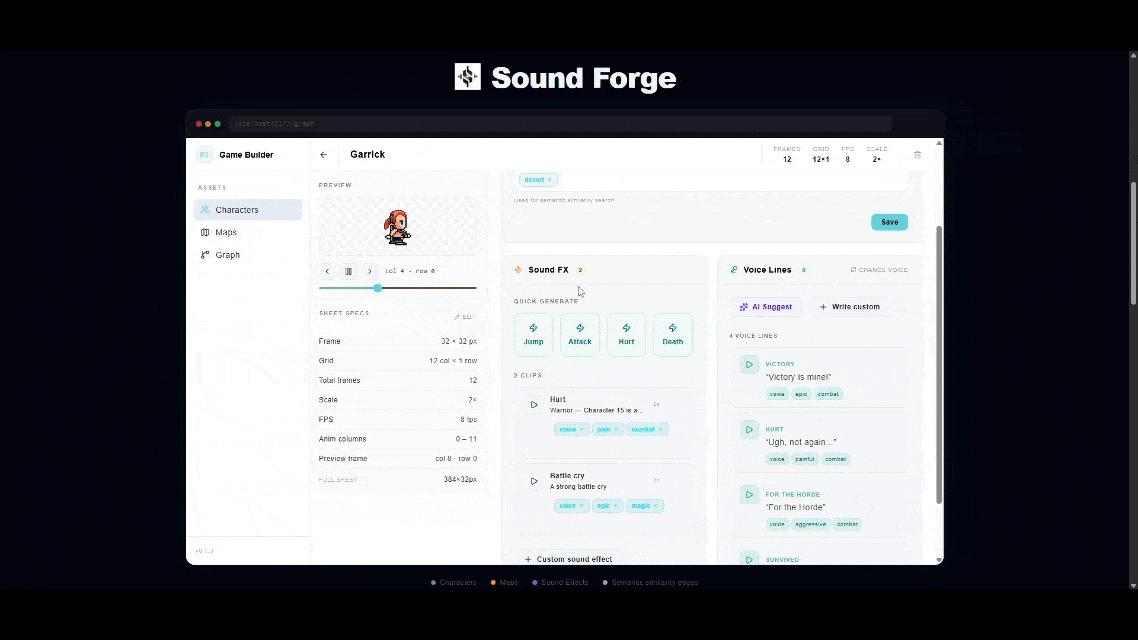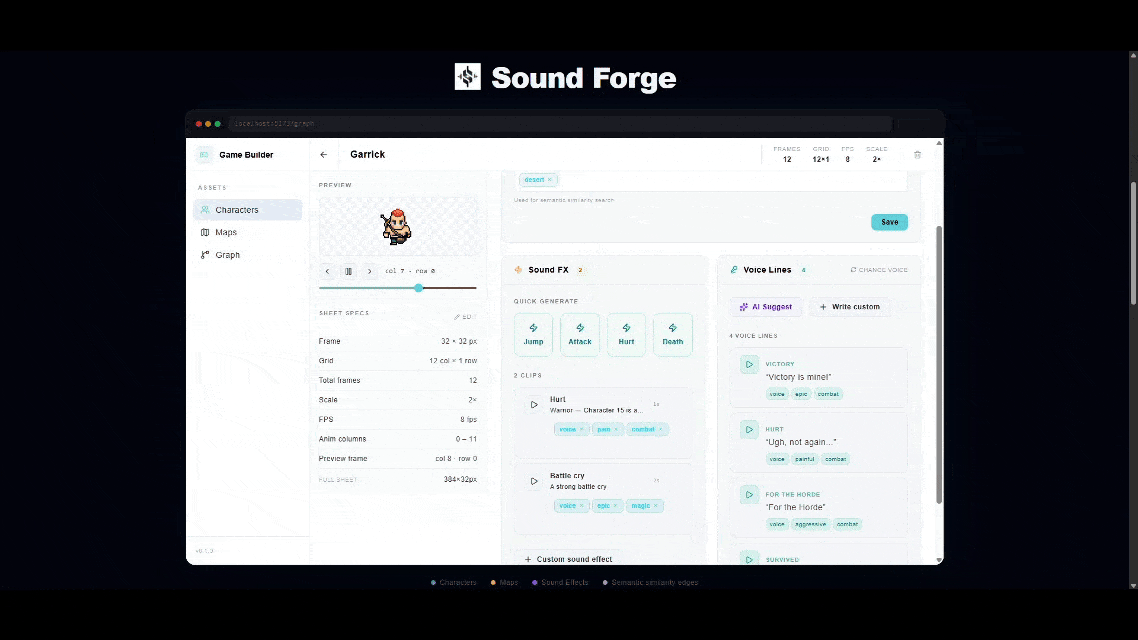
This week I build SoundForge! SoundForge is a tool to help game developers manage sounds for their characters and maps by generating unique voices, sound effects and music with Elevenlabs. So many new game developers get overwhelmed with all the aspects of game development and SoundForge is here to make that a little easier. SoundForge also takes advantage of TurboPuffer's vector database to map out all the relationships between characters, maps and even sounds so game developers can make sure the store and lore stays in line.